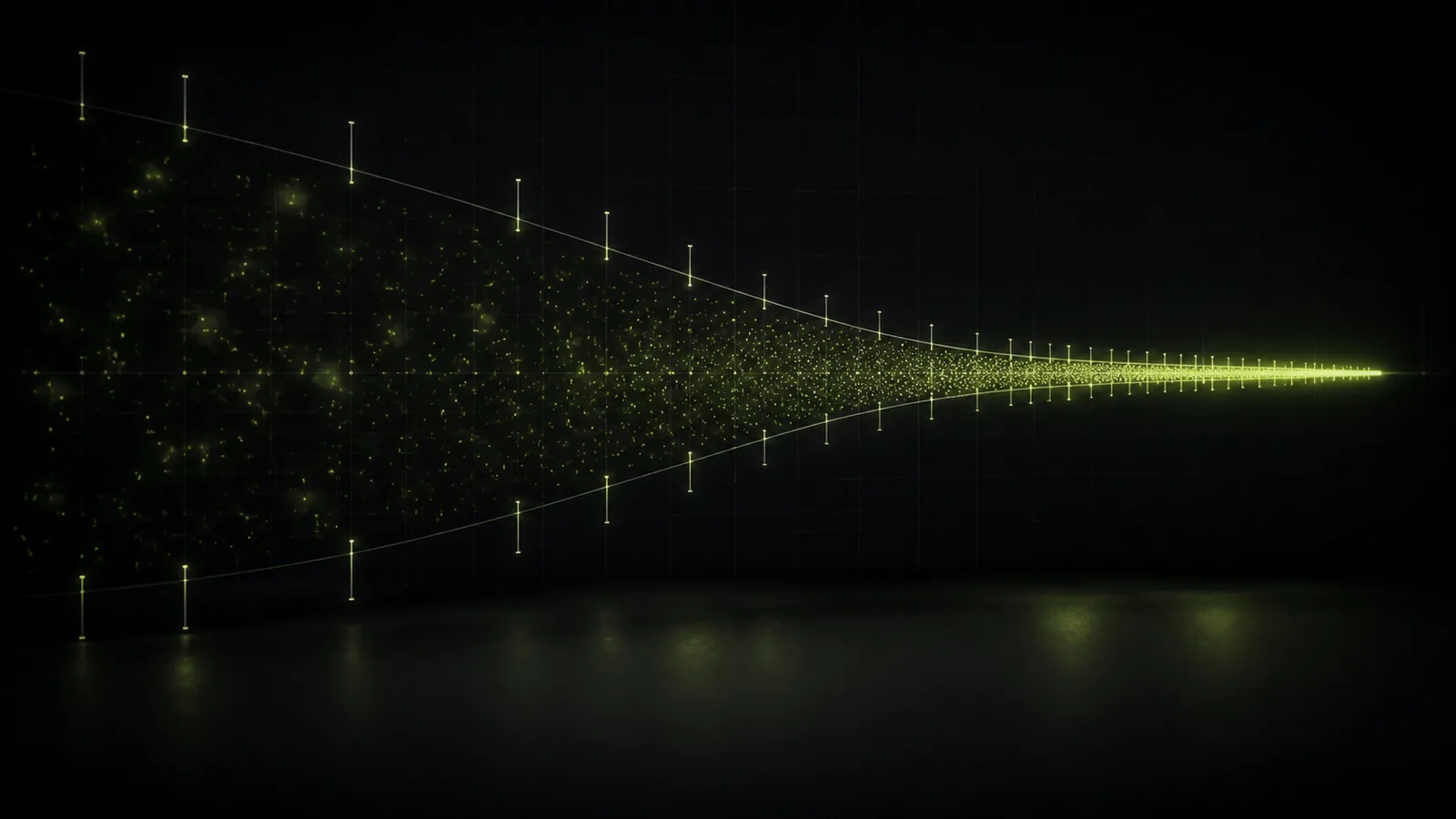
Example 1: The same coin, different stories
A break-even system (true expectancy zero) tested over 20 trades will, by chance, show a positive result almost half the time, sometimes a strongly positive one. Over 400 trades that same zero-edge system clusters tightly around zero and the illusion disappears. The lesson: a positive small-sample backtest is consistent with no edge at all, so the burden is on the sample, not the headline number.